Setting up Stackdriver Logging for Non-GCP Kubernetes Cluster
Aug. 28, 2019
Stackdriver is a fleet of software that is similiar to DataDog, but with a very small cost associated to it.
For homelabs, it's essentially free. My experiments has been around getting K8s connected to Stackdriver logging by not using fluentd (which is the recommended Stackdriver way).
My experiments are using fluent-bit to send log data to Stackdriver.
For this tutorial you'll need some files locally:
gcp.json # gcp auth details
configmap.yaml # fluent-bit logging
daemonset.yaml # fluent-bit daemon set
You can get the gcp.json file by setting up a service account.
I followed this tutorial here to get my gcp.json.
The configmap.yaml holds the configurations for fluent-bit.
Initially I ended up passing all logs to Stackdriver, but this resulted in a ton of noise that would have pushed me outside the free tier.
Hint hint, setup alerts to get a good understanding of how much you are logging.
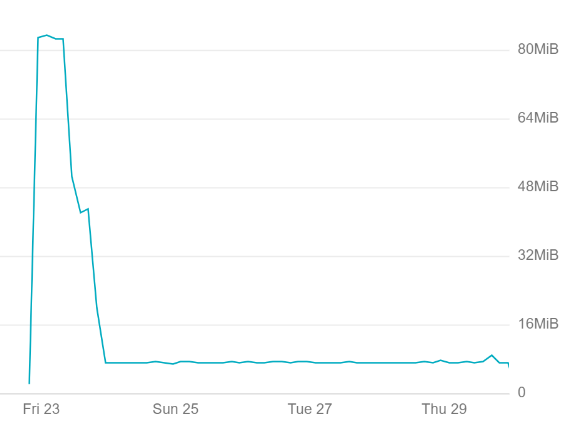
Large spike in logged data before I filtered out namespaces
What I did to manage this was think about my logging needs.
For my particular needs I only needed logs for my own namespaces.
By using a grep filter with fluent-bit you can remove namespaces that you don't want to push to your logging host.
I ended filtering these namespaces out:
- kube-system
- openebs
- metallb-system
- logging
If you wanted to filter on an annotations instead fluent-bit can do that as well, but that is left up to the reader.
Here is my configmap.yaml:
The daemonset.yaml sets up fluent-bit to only run one copy on each node in your cluster.
Here is my daemonset.yaml below:
I ended up setting up sealed-secrets for holding my gcp.json. When storing a JSON file within a secret I typically use a initialization container to convert it from base64 into a shared volume before letting the real container use it.
Here is my script to get sealed-secrets working:
Awesome, that's it. You should now be logging to Stackdriver.
comments powered by Disqus